SSD Data Tiering Is Generally Available
Dragonfly SSD Data Tiering is now GA. Scale beyond RAM limits on a single node — no resharding, no code changes. The only source-available Redis-compatible store with SSD tiering.
June 1, 2026
Five months ago, we shipped the initial release of Dragonfly SSD Data Tiering. Since then, dozens of teams have deployed it in production. Today we're calling it generally available.
GA means the architecture is stable, the edge cases are handled, and we're confident putting it in front of workloads that can't afford surprises. Dozens of production deployments across feature stores, session caches, and leaderboard workloads bear that out.
We are moving support beyond strings and are actively working on experimental support for list and hash datatypes. We have conducted multiple experiments with popular applications and frameworks and saw great results - lower memory usage without lower throughput.
SSD Data Tiering is now GA in the Dragonfly Community Edition, get started by visiting the docs. It is also available in beta for Dragonfly Cloud; if you want early access, get in touch here.
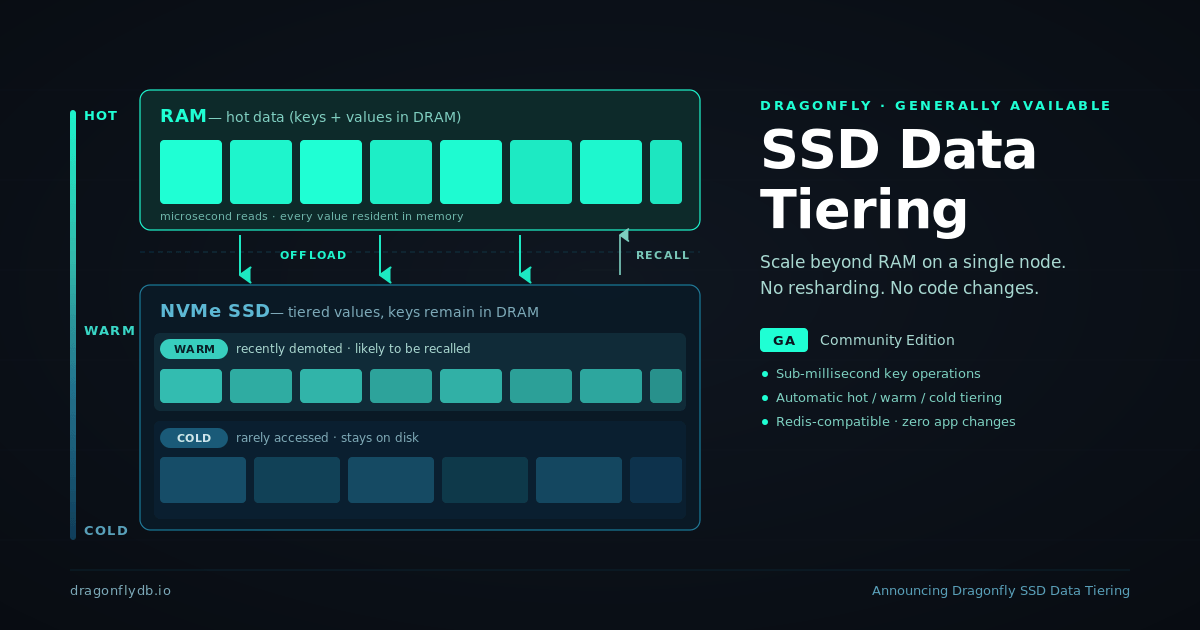
What It Does
Dragonfly’s SSD Tiering feature allows it to store data on local SSD drives, extending the potential size of a workload up to multiple times more than there is RAM available. Hot values remain in RAM to keep latency low, while Dragonfly's asynchronous nature allows it to saturate the SSD drive and reach high throughputs. Most importantly - this feature works transparently and does not require any application code changes.
The Only Source-Available Redis-Compatible Store With SSD Tiering
Other in-memory data stores such as Redis and Valkey do not support SSD tiering. If you're running either and your dataset has grown past your RAM budget, your options are to add more memory or shard across more nodes. Dragonfly is the only source-available, Redis-compatible in-memory data store that lets you extend capacity to local NVMe SSDs -- transparently, without API changes, and without touching your application.
Meesho: 300GB Working Set, 70% Cost Reduction
Meesho, one of India's largest e-commerce platforms, serves 175 million annual transacting users and runs some of their most critical caching infrastructure on Dragonfly. One of their critical workloads -- a memory-bounded cache with a 300GB working set and 45GB RAM capacity running at ~30K ops/sec -- was the proving ground for SSD tiering.
Before tiering, running that workload as a pure in-memory store meant paying for a large memory footprint while leaving CPU underutilized. They had previously adopted different enterprise solution but when Dragonfly's tiering support became available, they tested the same P0 workload on it and found 20-25% lower latencies at equivalent load, alongside roughly 70% cost savings for the same cache footprint. They've been running that workload on Dragonfly's tiering-based cache for two months with consistent performance throughout.
"Setup was genuinely straightforward -- no complex flags, no fiddly configuration. Dragonfly delivered on both performance and economics without the operational tax we expected."
-- Yash Shah, SDE@ Meesho
The Meesho result also illustrates the right framing for SSD tiering: it's not just about datasets that can't fit in RAM. It's about workloads where a large fraction of data is warm or cold -- accessed infrequently enough that keeping it in DRAM is waste. A 300GB working set at 30K ops/sec fits comfortably on NVMe for the inactive portion, with RAM reserved for what's actually hot.
Dragonfly's Architecture
Traditional datastores are notoriously bottlenecked by disk I/O, forcing them to either stall the main request queue or rely on inefficient worker threads. Dragonfly bypasses these synchronous limitations by leveraging asynchronous io_uring APIs. Combined with a fiber-based execution model, Dragonfly simply yields the waiting request to handle other work, seamlessly resuming it when the disk read completes. Furthermore, because Dragonfly is multi-threaded, it can drive multiple parallel I/O queues to fully saturate the underlying SSD's throughput. This transforms disk latency from a bottleneck into a background event. Dragonfly uses the following strategies to deliver optimal performance:
- Keys always stay in RAM.
Only values are offloaded to disk. Keys, TTLs, and metadata always remain in Dragonfly's DASH table. This means that only a single disk read needs to be issued to fetch the whole value. Operations working only with keys and metadata like EXISTS and TTL do not require any disk reads. - A three-state data model, not just LRU.
Dragonfly keeps entries in three states: hot (RAM only), cold (SSD only, pointer in RAM), and cooled (written to SSD, RAM copy temporarily retained). This cooled state allows the value to be read immediately after without any disk reads, making it hot again, while on the other hand it also allows the value to become immediately cold, freeing up memory. - Small values are batched together.
In modern SSDs, the smallest physical unit of data that can be read or written is almost universally 4 kilobytes. This often results in write amplification, causing small writes to have the same time and bandwidth penalties as larger ones, increasing the I/O overhead multiple times. To solve this problem, small values are batched together to be written with a single disk operation, filling optimally a 4 kilobyte page. When many small values are deleted, a special defragmentation process rearranges them - Actively writing clients are throttled.
When crossing the offloading threshold, actively writing clients are throttled and new values are written directly to disk. This allows the instance to provide backpressure to avoid running out of memory while also seamlessly ingesting large volumes of data. - io_uring for non-blocking I/O.
Dragonfly uses the Linux io_uring interface (kernel 5.19+) for all disk operations. This provides a non-blocking interface for I/O submission and completion, allowing Dragonfly to batch many disk operations concurrently and fully saturate NVMe bandwidth. Conventional blocking syscalls can't do this. - Page cache bypass via O_DIRECT. Dragonfly manages its own caching layer. Letting the Linux page cache also cache tiered data would mean competing for the same RAM and paying the CPU cost of redundant kernel-level copies. Dragonfly uses O_DIRECT to skip the page cache entirely, keeping full control over what lives in memory.
New Features Are Bring Actively Developed - Tiering With Lists
For a long time data tiering in Dragonfly has been possible only for string values. In recent versions we have started to add support for more datatypes. Since version 1.39, we support offloading of lists. For now, support of this feature is experimental.
In Dragonfly, lists are implemented as doubly linked lists of listpack nodes. “Listpack” is a redis-specific efficient binary encoded format for list storage with different datatypes. Because lists are very often modified and accessed starting from either end and rarely directly in the middle, the middle section nodes are perfect targets for offloading. For example, worker queues that read from one end and append to the other are a perfect fit for this approach. New jobs are read and written directly from memory, whereas the long queue of pending tasks in between is placed on disk.

Here is how to use this feature:
- It can be enabled with the `--tiered_experimental_list_support` flag
- The `list_tiering_threshold` configures starting since what distance from either end list nodes should be offloaded, 0 means disabled
A good candidate, but not the only one, is the Python job processing framework Celery, relying on Dragonfly or Redis for job storage. Celery uses a single list of all the pending jobs. In one of our experiments, we were able to reduce the memory usage of Celery to almost zero, while maintaining roughly the same throughput.
Tiering With Small Hashmaps
Small hashmaps, referred to as “hashes” in Redis, are also now supported for offloading with tiering in Dragonfly since version 1.39. The mechanics for hash tiering are similar to those for strings - everything is handled transparently.
A practical use case is with Feast, the Python-powered ML feature store framework, which uses hashes to store entries in Dragonfly. Since ML datasets for inference often reach many dozens of gigabytes in size, tiering allows rarely accessed documents to be stored on disk in exchange for slightly elevated latency, freeing up valuable RAM.
Only hashes that are relatively small in size can be offloaded. Here is how to enable this feature:
- It can be enabled with the tiered_experimental_hash_support flag
- The flag listpack_max_bytes (default 1024) controls the maximum total size of a hash in bytes
- The flag listpack_max_field_len (default 64) controls the maximum size of a single hash field
With our Feast experiment, we saw a 35% throughput decrease compared to pure RAM setup while running the instance on nearly zero memory usage. This allows you to scale your workload multiple times while sacrificing only a fraction of the performance.
Restrictions and Configuration
Note: As of now, the experimental features are not supported by snapshotting or replication. Full support is available only for the String datatype.
A few other constraints to be aware of:
- Keys and metadata always remain in RAM. Only values are offloaded.
- HyperLogLog and BITOP operations require data to be in memory.
- Durability is the same as standard Dragonfly -- tiering is a capacity extension, not a persistence layer. Use snapshots or HA replicas for durability.
To run Dragonfly with tiering:
./dragonfly --maxmemory=20G \
--tiered_prefix=/mnt/fast-ssd/dragonfly-tiered-file \
--tiered_offload_threshold=0.2
This starts Dragonfly with a 20GB RAM limit and begins offloading aggressively when memory utilization crosses 80%. The tiering engine manages the rest.
While it is technically possible to run Dragonfly in almost only-tiering mode with `tiered_offload_threshold=1.0`, it is preferable to leave a little leeway for operations to be batched together and executed in the background. This will noticeably improve throughput and decrease latency.
Full configuration options and monitoring guidance: https://www.dragonflydb.io/docs/managing-dragonfly/tiering
Get Started
SSD Data Tiering is GA today in Dragonfly Community Edition -- visit the docs to get started: https://www.dragonflydb.io/docs/managing-dragonfly/tiering.
SSD tiering is in beta for Dragonfly Cloud on AWS and GCP. If you want early access, get in touch: https://www.dragonflydb.io/request-demo.
If you're running a workload where dataset size has become the binding constraint -- feature stores, session stores, recommendation caches, large leaderboards -- this is the path to scaling vertically without a cluster overhaul.
Want to go deeper? The engineers who built SSD tiering are hosting a live technical walkthrough where they'll cover the architecture in detail and take questions. Register for the webinar here: https://www.dragonflydb.io/events/beyond-ram-a-technical-deep-dive-into-dragonfly-ssd-data-tiering.
Try it and let us know what you find. The community is on Discord and GitHub.
